![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy.png)



本連載は、コンピューター・サイエンス&テクノロジ専門誌『Interface』編集部と、株式会社アクセルの共同企画です。記事を担当するのは、現役のきゅうり農家を営みながらプログラミングや開発を行う、小池 誠さん。連載では製作やアプリ開発を通してエッジAIの技術解説を行います。
AIの推論モデル実行には、アクセルのエッジAI用推論エンジン「アイリアSDK(ailia SDK)」を使います。
2025年7月には著者による「農業×エッジAIセミナ」を開催する予定です。
※本企画は『Interface』2025年7月号に掲載された記事を再編集したものです。
第二回に続き、今回は虫を捕ばくするための粘着シートを用いて、虫が付いていない正常画像と、虫が付いた異常画像を収集後、学習させて推論モデルを作ります。モデルができたら評価を行います。
異常検知で高い性能を発揮する学習モデルPatchCore
●異常検知は検査業務を自動化/高精度化する目的で研究が進んでいる
画像異常検知とは、正常画像を学習し、新たに入力された画像がどの程度正常らしくないかを定量的なスコア(異常スコアと呼ぶ)として評価し、異常を検知する技術のことです。製造業の外観検査や医療画像診断など、人が目視で行っていた検査業務を自動化/高精度化することを目的に研究開発が進んでいます。特に近年はディープ・ラーニングを活用した手法が多く研究されており、代表的な手法にPatchCore(パッチコア)やEfficientADなどがあります。図1はPatchCoreによる異常検知の例です(※注1)。正常/異常の判定だけでなく、異常がある部位の可視化を行うことができます。
※注1:PatchCoreは産業用異常検知の分野で非常に重要なデータセットであるMVTec ADベンチマークにおいて性能が実証されている。
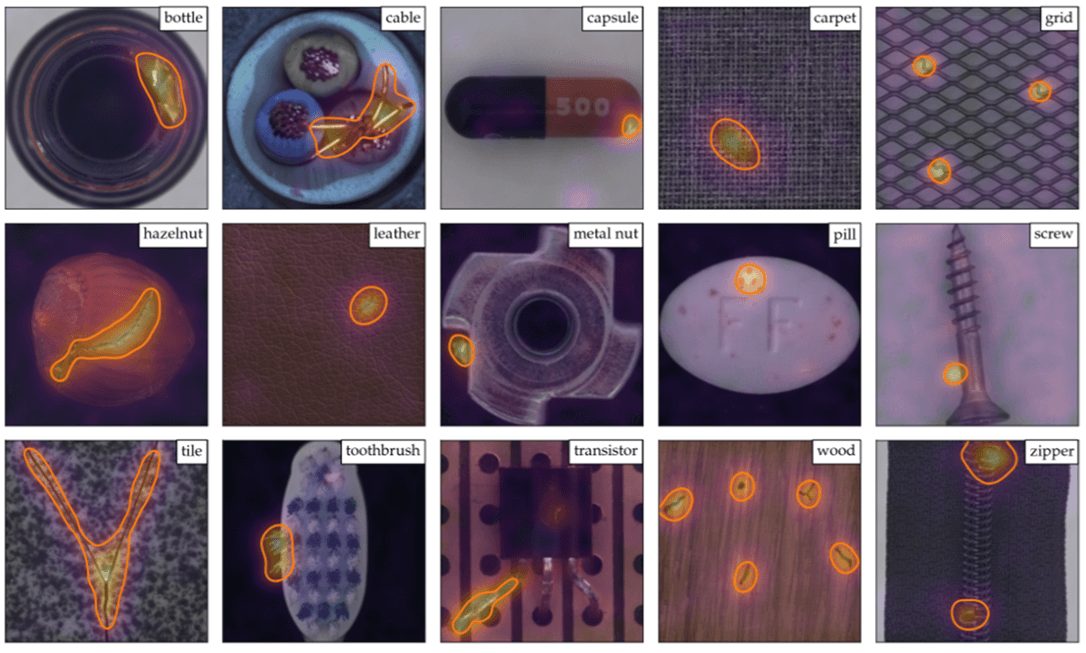
出典:引用文献(1) (2) (3) ※本記事の文末に記載
●PatchCore の特徴…異常画像が少なくても大丈夫
PatchCoreは異常検知で高い性能を発揮する学習モデルです。PatchCoreでは、事前学習済みモデルの重みを更新する追加学習(ファイン・チューニング)は行いません。代わりに事前学習済みモデルを用いて、正常な画像データから抽出した特徴量を集約し、画像データの代表的な特徴量をメモリ・バンクに保持します。異常検知を行う際は、検査対象の画像データから同様に特徴量を抽出し、メモリ・バンクに保持された特徴量と照らし合わせることで、正常/異常の判定を行います。従ってPatchCoreの学習時には誤差逆伝搬法を使った学習ループを回す必要がなく、比較的素早く高精度な異常検知モデルを構築できます。
●こんなときに導入を検討する
画像異常検知の大きな特徴の1つは、正常画像のみを用いて学習できる点です。一般的な画像認識モデルを学習する際には、教師あり学習が用いられるため、分類したい各ラベルに対応する画像データをそれぞれ大量に集める必要があります。一方、画像異常検知モデルの学習では、正常かそれ以外かを分類するという外れ値検知の考え方に基づいており、正常な画像データのみを使って学習を行うことで、異常画像(=外れ値)を検知します。このような仕組みであるため、画像データ収集のコストを大幅に軽減できるという大きなメリットを持っています。
従って、次のようなケースにおいては、画像異常検知アルゴリズムの導入を検討してみる価値があるでしょう。
- 異常データの収集が根本的に困難な場合(発生頻度が極端に少ないなど)
- 未知の異常も検知したい場合
- 異常の種類が多様でラベル付けコストが高すぎる場合
- 学習データ収集のコストを削減したい場合
ステップ1…画像データの収集
●粘着シートの画像を集める
画像異常検知モデルの学習のためまず粘着シートを撮影して画像データを収集します。粘着シートの撮影は、小さな虫でも明瞭に認識できるように、ラズベリー・パイPiCameraV3で対応可能な2304×1296の解像度に設定しました。ただし、このままでは1枚の画像データのサイズが大きくなりすぎるため、図2のように粘着シートの中心部から縦1024×横1792ピクセルの領域を切り出し、256×256のタイル状に分割しました。そして図3のように、新品の粘着シートの画像を正常データとし、虫の付いた粘着シートの画像を異常データと定義しました。
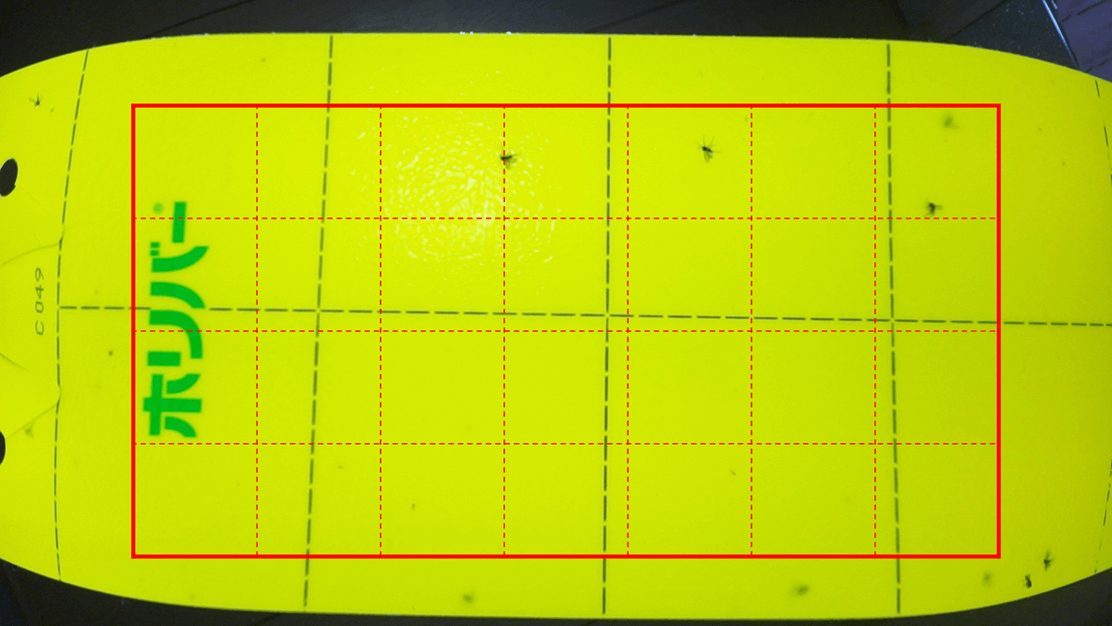

●正常画像2400枚と異常画像50枚を集める
画像データの収集は、前回作成済みのハードウェアを用いて、実際に使用する温室ハウス内で行いました。まず、新品の粘着シートを10枚用意し、クリップに取り付ける位置を少しずらしながら、1枚につき5枚の画像を撮影しました。次に、撮影した粘着シートの画像から、解像度256×256の画像を28枚切り出し、さらにランダムな座標から20枚の画像を追加で切り出しました。
最終的に、正常画像データは、10×5×(28+20)の合計2400枚を収集しました。一方、異常画像データの収集は、評価用として害虫が付着した粘着シート5枚から、合計50枚の異常画像を取得しました。
ステップ2…データセット作り
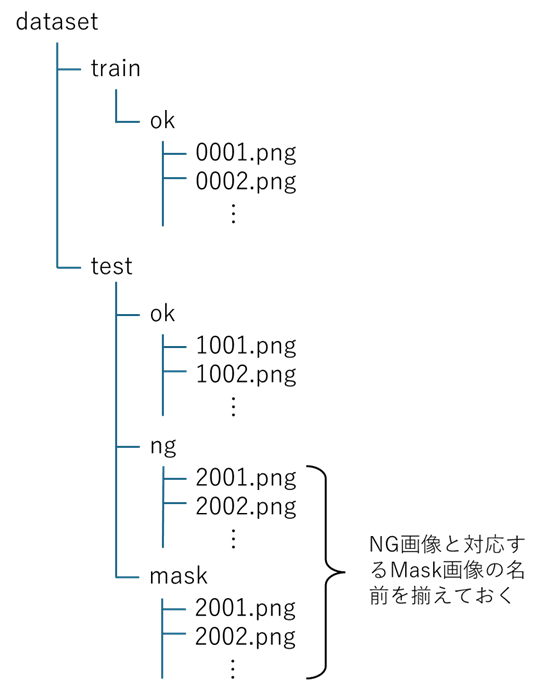
集めた画像データを整理し、データセットを構築します。図4に画像異常検知に対応したデータセットのフォルダ構成を示します。まず、ルート・フォルダ(図4のdataset)には、学習用データを保存するtrainフォルダと評価用データを保存するtestフォルダを配置します。ここでマスク画像とは、図5に示すように背景は黒、異常部位を白で示した画像のことです。マスク画像は、GIMPなどの画像編集ソフトウェアや専用ツールを用いて作成し、異常画像との対応が分かるように同じファイル名にしておきます。

(左)NG画像 (右)マスク画像
ステップ3…モデルの学習
●使用するライブラリとアルゴリズム
画像異常検知モデルの学習には、Anomalib(※注2)というライブラリを使用します。Anomalibは、ディープ・ラーニングを用いた異常検知アルゴリズムを簡単かつ迅速に利用できるPythonライブラリです。このライブラリを活用することで、MVTecなどのデータセットや、自前で用意したデータセットを使い、PaDiMやPatchCoreといったディープ・ラーニングに基づく主要な異常検知アルゴリズムを試すことができます。
今回はAnomalibで使用できるアルゴリズムの中から、PatchCoreとEfficientADを試します。それぞれの特徴を表1に示します。MVTecデータセットのベンチマーク結果では、EfficientADの方が高い精度を示していますが、一般的に異常検知の精度は対象とするデータセットによって大きく変動することが知られています。特に、バックボーンによる特徴量抽出や異常スコアの算出方法が、対象のデータと適切にマッチ。していることが重要です。そのため、特定のアルゴリズムで十分な精度が得られない場合は、ほかのアルゴリズムも試してみる価値はあります。
※注2:Anomalib,https://github.com/openvinotoolkit/anomalib
| アルゴリズム | 常スコアの算出方法 | バックボーン | MVTecに対する精度(AUC) | 特 徴 |
|---|---|---|---|---|
| PatchCore | k近傍探索を用いた特徴類似度によるスコア付け | ResNet18 | 0.973 | さまざまな分野(データ)で汎用的に用いることができる手法であるが,メモリ・バンクを構築するためメモリ使用量が大きく,推論のたびにk近傍探索の計算に時間がかかる |
| Wide ResNet50 | 0.98 | |||
| EfficientAD | 教師モデルと生徒モデルが出力する特徴の差異に基づくスコア付け | EfficientNet-Small | 0.982 | メモリ消費や計算量を抑えることを目的としたモデルであり,モバイル・デバイスなどでの実行が想定されている |
| EfficientNet-Medium | 0.975 |
●環境構築
今回は学習環境として、Google Colaboratory(以降、Colab)を利用します。Colab環境にAnomalibをインストールする方法をリスト1に示します。注意点として、最新のmatplotlibを用いると実行途中でエラーが発生するため、matplotlibは3.7.0をインストールし直す必要があります。また、インストールした後はColabのセッションをリセットしてmatplotlibをインポートし直してください。主要なライブラリのバージョンを表2に示します。
# Colabで実行してください(リスト1)GoogleColabにAnomalibをインストールする
!pip install lightning kornia FrEIA python-dotenv open_clip_torch openvino-dev onnx anomalib
!pip install -U matplotlib==3.7.0
# ここで一旦セッションをリセット
| ライブラリ | バージョン |
|---|---|
| anomalib | 1.2.0 |
| torch | 2.5.1+cu124 |
| torchvision | 0.20.1+cu124 |
| lightning | 2.5.0.post0 |
| kornia | 0.8.0 |
| FrEIA | 0.2 |
| python-dotenv | 1.0.1 |
| open_clip_torch | 2.30.0 |
| openvino-dev | 2024.6.0 |
| onnx | 1.17.0 |
| matplotlib | 3.7.0 |
●学習のためのコード
学習のためのコードをリスト2、リスト3に示します。始めにステップ2で作成したデータセットをColab環境にアップロードしてください。データセットの読み込みはFolderクラスを用います。各パラメータは次の通りです。
from pathlib import Path
from anomalib.data.image.folder import Folder
from anomalib.engine import Engine
from anomalib.models import Patchcore
# 画像データの読み込み
datamodule = Folder(
name="sheet",
root=Path("datasets/"),
normal_dir="train/ok",
normal_test_dir="test/ok",
abnormal_dir="test/ng",
mask_dir="test/mask",
image_size=(256,256),
train_batch_size=4,
eval_batch_size=4,
seed=42,
)
datamodule.setup()
print("学習データ数:", len(datamodule.train_data))
# PatchCoreモデルを作成する…①
model = Patchcore(
backbone="wide_resnet50_2", # または,“resnet18”
)
# エンジンを作成する
engine = Engine()
# モデルをトレーニングする
engine.fit(model, datamodule=datamodule)
# モデルを評価する…②
results = engine.test(model, datamodule=datamodule)
print(results)
(リスト2)学習コード1…PatchCore
from pathlib import Path
from anomalib.data.image.folder import Folder
from anomalib.engine import Engine
from anomalib.models import EfficientAd
# 画像データの読み込み
datamodule = Folder(
name="sheet",
root=Path("datasets/"),
normal_dir="train/ok",
normal_test_dir="test/ok",
abnormal_dir="test/ng",
mask_dir="test/mask",
image_size=(256,256),
train_batch_size=1,
seed=42,
)
datamodule.setup()
print("学習データ数:", len(datamodule.train_data))
# EfficientADモデルを作成する…①
model = EfficientAd(
model_size=”small” # または,”medium”
)
# エンジンを作成する
engine = Engine(
max_epochs=100,
)
# モデルをトレーニングする
engine.fit(model, datamodule=datamodule)
# モデルを評価する…②
results = engine.test(model, datamodule=datamodule)
print(results)
(リスト3)学習コード2…EfficientAD
- root:データセット・フォルダへのパス
(./dataset) - normal_dir:学習に用いる正常データ
(train/ok) - normal_test_dir:評価に用いる正常データ
(test/ok) - abnormal_dir:評価に用いる異常データ
(test/ng) - mask_dir:評価に用いるマスク・データ
(test/mask) - image_size:入力画像の縦横サイズ
- train_batch_size:学習時のバッチ・サイズ
- eval_batch_size:評価時のバッチ・サイズ
- seed:乱数シード
ここで、学習時にOutOfMemoryエラーが発生する場合は、バッチ・サイズを小さくしてください。なお、EfficientADの学習では、train_batch_sizeを1に設定する必要があります。
学習のテクニック
●1.モデル・バックボーンの設定
PatchCoreとEfficientADでは、画像特徴を抽出するバックボーンを設定できます(リスト2、リスト3の①)。PatchCoreのデフォルトのバックボーンはwide_resnet50_2ですが、より小さいモデルを使用したい場合はresnet18が選択できます。一方、EfficientADのデフォルトはsmallですが、より大きなモデルを使用したい場合はmediumが選択できます。
一般的には、モデル・サイズが大きい方が精度が高くなる傾向にあると考えられますが、画像異常検知の場合は必ずしもそうではないようです(表1)。推論速度については、モデル・サイズが小さい方が速くなります。
●2.学習ログの可視化
Anomalibでは、TensorboardやWeights&Biases(Wandb/※注3)などの学習ログを可視化する機能が搭載されています。近年人気のあるログ可視化サービスWandbを使用する場合は、リスト4のようにコードを編集してください。
なお、Wandbを使用する場合は、事前にWandbのWebページでアカウント登録が必要です。学習を開始する際にAPIキーの入力が求められるため、アカウントに紐付いたAPIキーを入力してください。
※注3:Weights&Biases,https://wandb.ai/site/ja/
from anomalib.loggers import AnomalibWandbLogger
# エンジンを作成する(ロガーをWandbに設定する場合)
engine = Engine(
max_epochs=100,
logger=AnomalibWandbLogger(
project="EfficientAD",
log_model=False, # モデルをサーバに保存する場合はTrue
)
)
(リスト4)Wandbによるロギング
●3.学習途中からの再開
Colab上で長時間学習(EfficientADなど)を行う場合、学習途中でランタイムとの接続が切れてしまい学習が中断してしまうことがあります。そのような場合に備えて、途中から学習を再開できるようにする方法をリスト5に示します。
まず、学習途中のモデルが削除されないように、Googleドライブをマウントして(リスト5の①)、学習途中のモデルがドライブ上に保存されるようにroot_dirパスを変更します(リスト5の②)。そして、学習を実行する際に前回学習途中に保存したチェック・ポイントを読み込むように設定します(リスト5の③)。
# Googleドライブをマウント…①
from google.colab import drive
drive.mount('/content/drive')
# エンジンを作成する…②
engine = Engine(
max_epochs=100,
default_root_dir="drive/MyDrive/<保存先フォルダ名>",
)
# モデルをトレーニングする…③
engine.fit(
model,
datamodule=datamodule,
ckpt_path="drive/MyDrive/<保存先フォルダ名>/…/model.ckpt"
)
(リスト5)学習途中からの再開
モデルの評価
●評価指標は4つ
学習したモデルの評価を行います(リスト2、リスト3の②)。コードを実行すると評価結果として、次の4つの評価指標が表示されます。
- image_AUROC :正常/異常判定のAUROC
- image_F1Score:正常/異常判定のF1スコア
- pixel_AUROC :ピクセル単位の正常/異常判定のAUROC
- pixel_F1Score:ピクセル単位の正常/異常判定のF1スコア
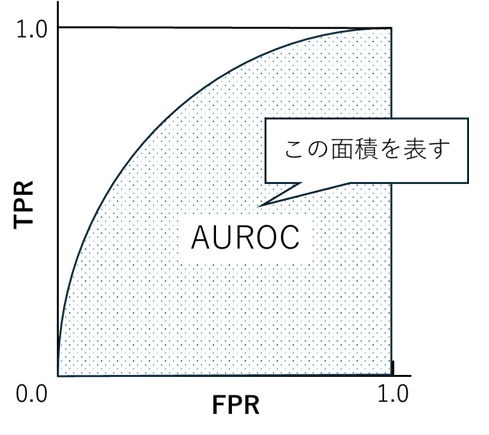
まず、Area Under Receiver Operating Characteristiccurve(AUROC,または単純にAUC)は、2値分類タスクでよく使用される評価指標で、全てのしきい値における偽陽性率(FPR)と真陽性率(TPR)をプロットしたROC曲線(分類問題におけるモデルの性能を評価するために使われるグラフ)の下の面積を表します(図6)。正常と異常をランダムに判定した場合、AUROCは0.5となり、判定精度が高くなるにつれて1.0に近づきます。
次にF1スコア(またはF値)は、分類タスクに対する評価指標で、適合率(Precision)と再現率(Recall)を調和平均で表した指標です。F1スコアの範囲は0.0〜1.0で表され、値が大きいほど適合率と再現率がバランスよく精度が高いことを意味します。
●結果
PatchCoreとEfficientADの評価結果を、学習に使用した学習データ数別に表3に示します。EfficientADは、MaxEpoch=100まで学習を行った結果を示しています。この結果から、まずPatchCoreを用いた方が全体的に評価指標の精度が高いことが確認できました。また、学習データ数が10枚程度でも、pixel_F1Scoreを除けば約80%の精度が得られており、異常/正常の判定のみであれば、学習データが少ない場合でも活用できそうです。
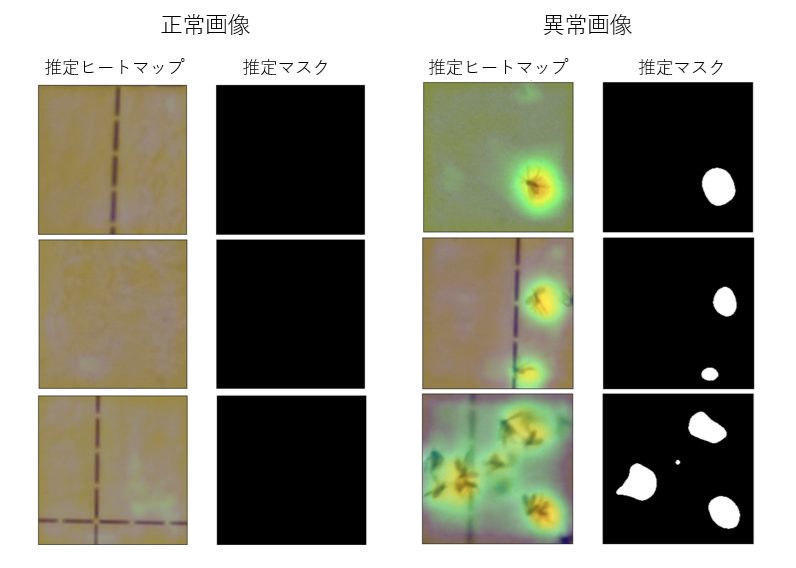
次にEfficientADは、学習データ数が500枚のときのみ、pixel_F1ScoreがPatchCoreを上回りましたが、それ以外はPatchCoreに劣る精度でした。テスト・データに対する推定結果の例を幾つか図7に示します。
なお、ColabのT4環境では、PatchCoreは学習データ数が1000以上になるとメモリ不足エラーが発生し、学習を実行できませんでした。
| Method | Train size | image_AUROC | image_F1Score | pixel_AUROC | pixel_F1Score |
|---|---|---|---|---|---|
| PatchCore | 10 | 0.862 | 0.759 | 0.932 | 0.257 |
| 50 | 0.996 | 0.809 | 0.958 | 0.337 | |
| 100 | 0.984 | 0.943 | 0.977 | 0.404 | |
| 500 | 1.000 | 0.980 | 0.978 | 0.445 | |
| 1000 | – | – | – | – | |
| 2900 | – | – | – | – | |
| EfficientAD | 10 | 0.755 | 0.807 | 0.735 | 0.202 |
| 50 | 0.745 | 0.821 | 0.749 | 0.113 | |
| 100 | 0.873 | 0.872 | 0.793 | 0.342 | |
| 500 | 0.963 | 0.863 | 0.811 | 0.507 | |
| 1000 | 0.961 | 0.869 | 0.803 | 0.472 | |
| 2900 | 0.982 | 0.936 | 0.809 | 0.27 |
ONNXモデルの保存
学習済みモデルをONNX形式で保存します。リスト6にモデル保存のためのコードを示します。コードを実行するとmodelフォルダの中に、model.onnxとmetadata.jsonという名前のファイルが作成されます。これらのファイルが学習済みモデルになりますので、後のアプリ実装で使用するためにダウンロードしておきます。
# 学習済みモデルの保存
from anomalib.deploy import ExportType
engine.export(
model=model,
export_root="./model",
export_type=ExportType.ONNX,
)
(リスト6)学習済みモデル(ONNX 形式)の保存
【引用文献】
(1)Karsten Roth, Latha Pemula;Towards Total Recall in Industrial Anomaly Detection, https://arxiv.org/pdf/2106.08265
(2)Paul Bergmann,Kilian Batzner,Michael Fauser,David Sattlegger,Carsten Steger;The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection;in:International Journal of Computer Vision 129(4):1038-1059,2021,DOI:10.1007/s11263-020-01400-4.
(3)Paul Bergmann,Michael Fauser,David Sattlegger,Carsten Steger;MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection;in:IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),9584-9592,2019,DOI:10.1109/CVPR.2019.00982.

小池 誠 氏
キュウリ農家、博士(情報学。大学卒業後、自動車部品メーカーにてソフトウェア・エンジニアとして勤務・退職後、2015年から農業に従事。現在は農業を行う傍ら、大学においてスマート農業に関する研究に取り組んでいる。

コンピューター・サイエンス&テクノロジ専門誌『Interface』
CQ出版社が発行するコンピュータ技術専門の月刊誌です。1974年の創刊以来、組み込みシステム、ソフトウェア、AI、IoTなど、時代とともに進化するコンピュータ技術を幅広く紹介しています。理論だけでなく、実践的なプログラミングや実機製作の記事も豊富で、エンジニアから学生まで、コンピュータ技術を深く学びたい読者に支持されています。
https://interface.cqpub.co.jp/
SHARE THIS ARTICLE












