![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy.png)



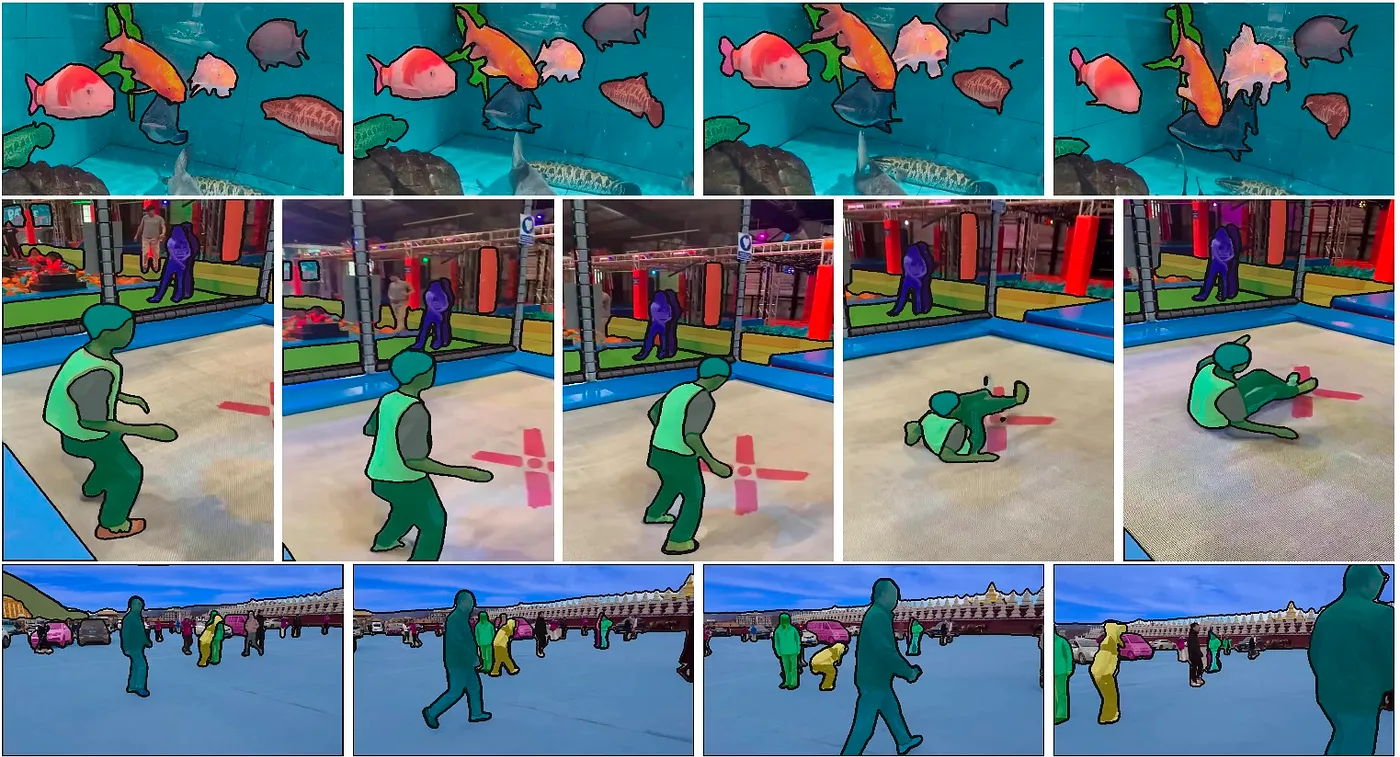
動画に対応した任意物体のセグメンテーションモデルであるSegmentAnything2の紹介です。
SegmentAnything2の概要
SegmentAnything2はMetaが開発して2024年7月に公開したセグメンテーションモデルの新バージョンです。2023年4月に公開されたSegmentAnythingよりも高精度化した上で、動画への適用も可能になっています。
https://github.com/facebookresearch/segment-anything-2
https://ai.meta.com/research/publications/sam-2-segment-anything-in-images-and-videos
SegmentAnything2のアーキテクチャ
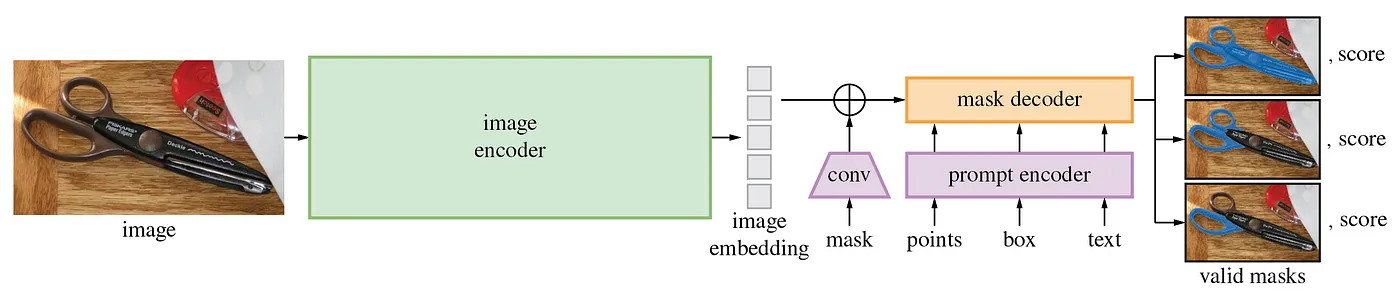
下記がSegmentAnything2のアーキテクチャです。静止画モードでは、画像をImage EncoderでEmbeddingした後、Prompt Encoderでプロンプトをベクトル化、Mask Decoderでマスク画像を生成します。SegmentAnything2では、セグメンテーションの領域を、mask、points、boxで指定することが可能です。

動画モードでは、現在のフレームのEmbeddingと、過去および未来のフレームのEmbeddingを元に、Memory AttentionでEmbeddingを補正します。また、ステップ1で動画をセグメンテーションした後、セグメンテーションできなかった部分のキーポイントを追加してステップ2で改善するような処理にも対応しています。
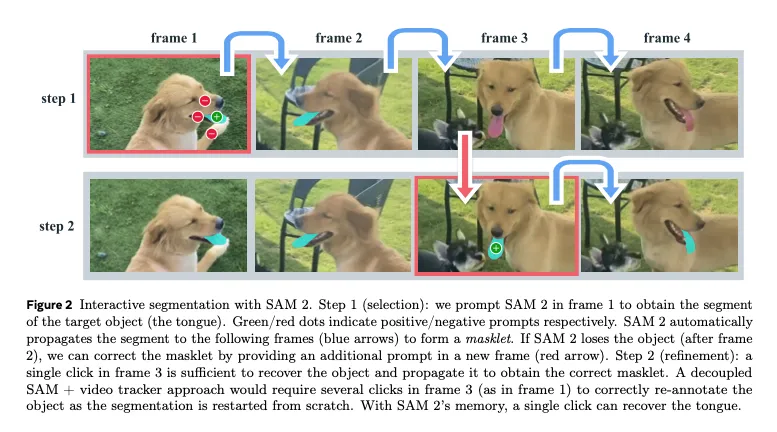
比較用のSegmentAnything1のアーキテクチャです。動画用にMemory AttentionとMemory Encoderが追加された以外は、SegmentAnythingと近しい構成になっています。なお、SegmentAnything2では、SegmentAnything1で論文上は対応していたtextは非対応になっています。ただし、SegmentAnything1でもtextの実装は公開されていませんでした。
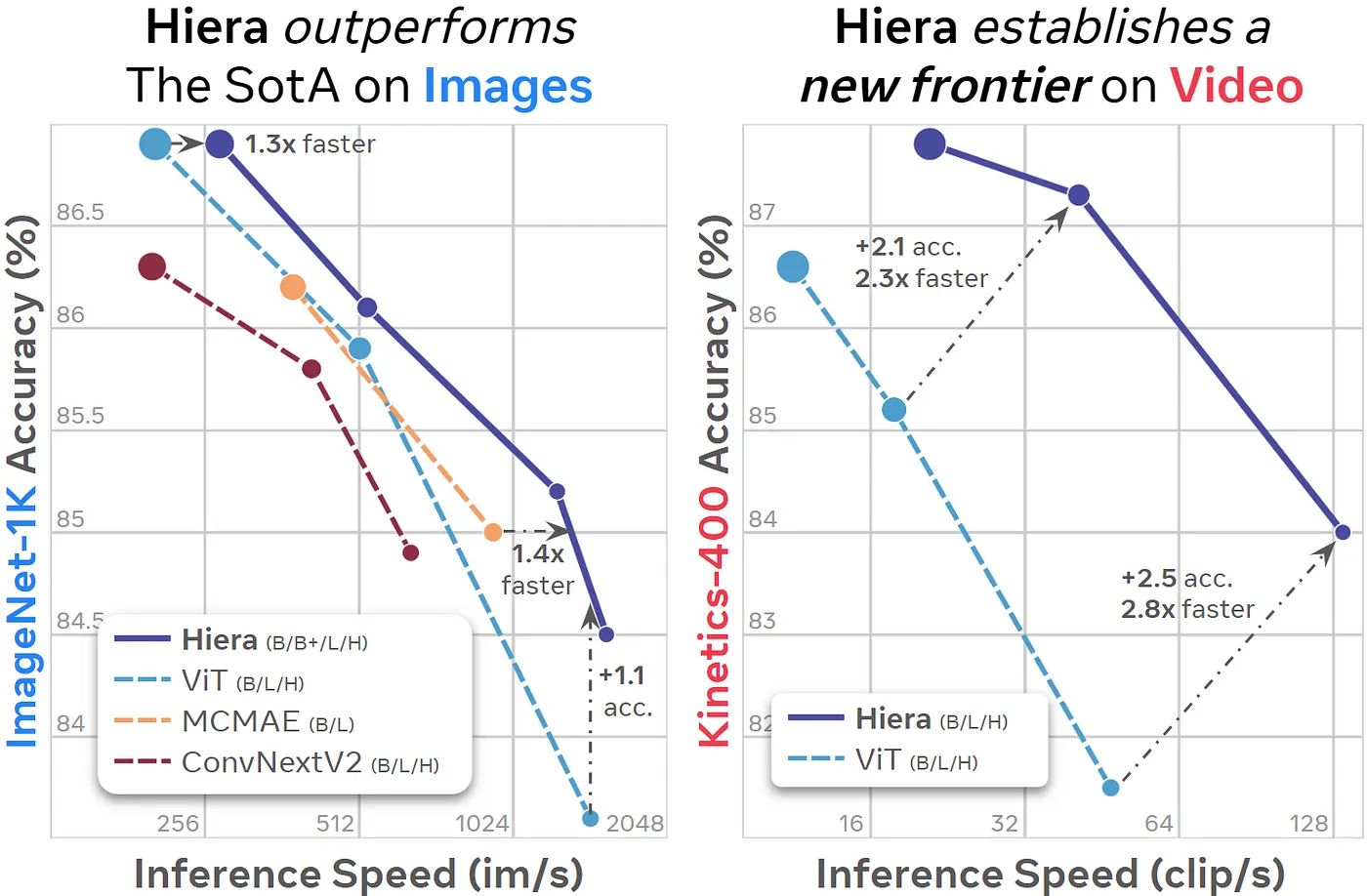
SegmentAnything1のImage EncoderはVITでしたが、SegemenyAnything2のImage EncoderはHieraを使用しています。HieraはMetaが開発した、階層型のVision Transformerです。VITは、ネットワーク内で空間解像度が変化しません。しかし、最初の方のレイヤーではそんなに多くの特徴量は不要で、逆に後のレイヤーではそんなに多くの空間解像度が不要であり、非効率です。Heraでは、ResNetのように、段階的に空間解像度を下げるアーキテクチャになっています。
HieraはVITに比べて、高速に推論することが可能です。そのため、SegmentAnything1よりもSegmentAnything2の方が高速に推論が可能です。
https://github.com/facebookresearch/hiera
データセット
SegmentAnything2は、SA-VというSegmentAnything2のために作成された動画データセットを使用してます。このデータセットは、50.9Kのビデオと、642.6Kのマスクで構成されます。

SegmentAnything1はSA-1Bデータセットを使用しており、1100万枚の静止画像と10億のマスクで学習されていますが、SegmentAnything2は、SA-1BとSA-Vをミックスして学習しています。
精度
静止画モードの精度です。SegmentAnything2は、SegmentAnythingよりも高精度かつ高速になっています。our mixでは、SA-1Bデータセットと、SA-Vデータセットをミックスして学習することで、精度が改善していることがわかります。

動画モードの精度です。SegmentAnything2は、動画のセグメンテーションタスクで最も高い性能を持っています。
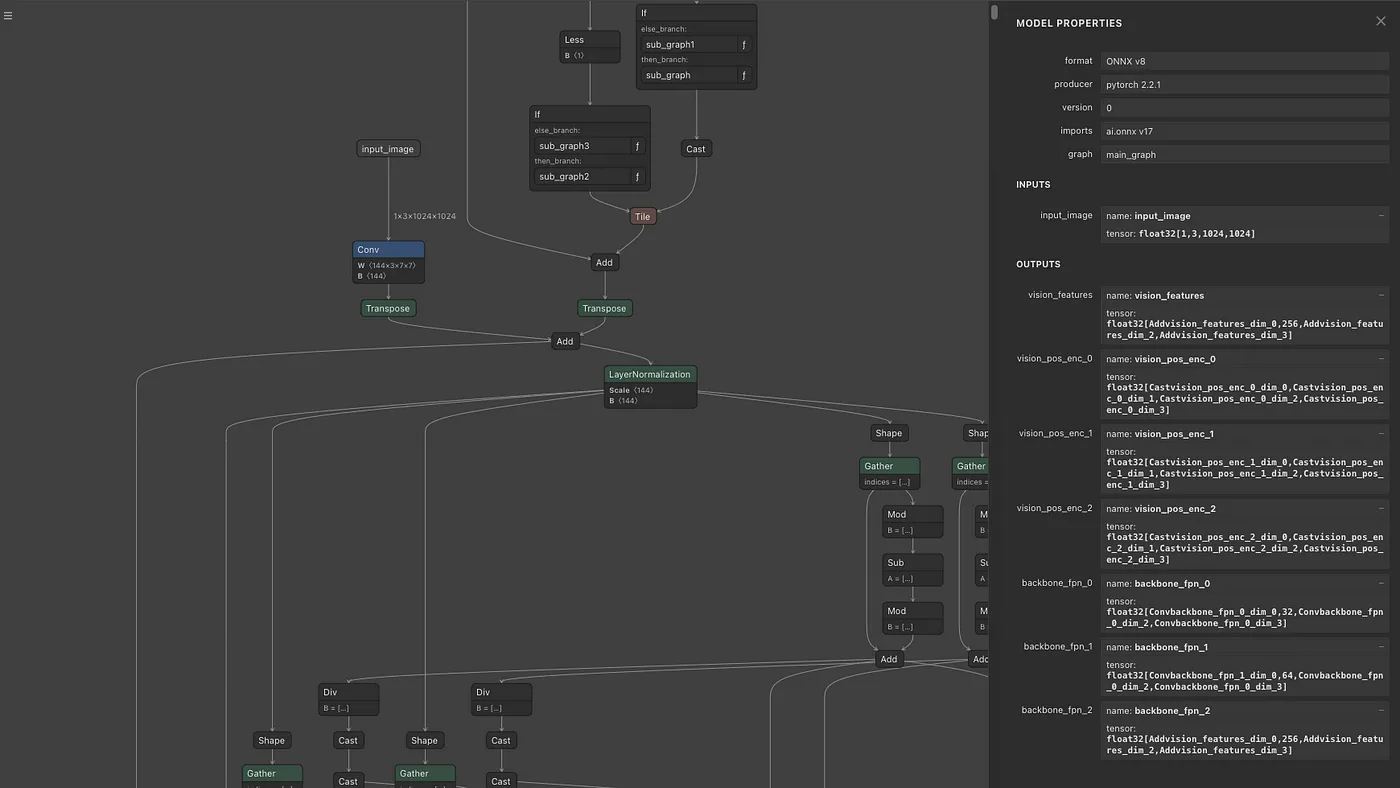
静止画モードの動作
Image Encoderにおいて、入力画像は、sam2/utils/transforms.pyで前処理され、RGB順で、mean = [0.485, 0.456, 0.406]、std = [0.229, 0.224, 0.225]で正規化されます。処理対象の画像サイズは1024×1024になります。リサイズではアスペクト比を保持しません。変換後の入力画像のShapeは(1, 3, 1024, 1024)になります。
Image Encoderの出力は、vision_features(最終層の特徴量)、vision_pos_enc(最終層を含む3階層)、backbone_fpn(最終層の3階層を含む特徴量、最終層はvision_featuresと等価)になります。このデータを、_prepare_backbone_featuresの後処理に通すことで、3階層のEmbeddingに変換します。上層をhigh_res_featsと呼び、下層をimage_embedと呼びます。high_res_feats = [(1, 32, 256, 256), (1, 64, 128, 128)]、image_embed = (1, 256, 64, 64)のShapeを持ちます。
Prompt Encoderの出力は、sparse_embeddingsとdense_embeddingsになります。sparse_embeddingsは、pointsとboxから計算されます。dense_embeddingsは、maskから計算されます。sparse_embeddingsのShapeは(1, N, 256)、dense_embeddingsのShapeは(1, 256, 64, 64)です。
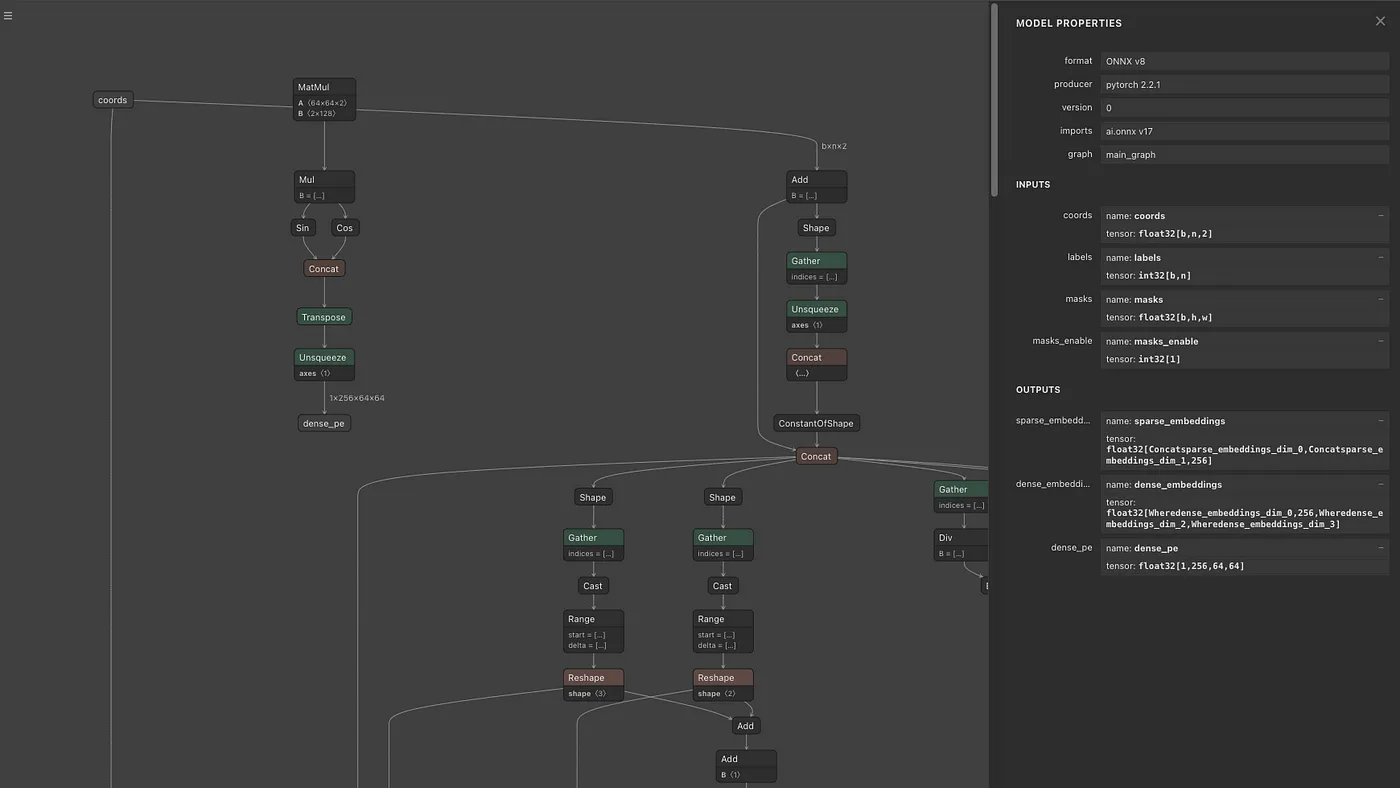
Mask Decoderの出力は、multi_mask_output = Trueの場合は3枚の256×256解像度のマスク画像と確信度になります。low_res_masksのShapeは(1, 3, 256, 256)、iou_predictionsのShapeは(1, 3)となります。low_res_masksは-32〜32のレンジでClampされます。デフォルトのmask_thresholdは0であるため、low_res_masksが0以下の場合は0、low_res_masksが0より大きい場合は1に2値化します。multi_mask_output = Falseの場合は1枚の256×256解像度のマスク画像と確信度になります。モデルとしては4枚の画像を出力しており、multi_mask_output = Falseの場合は最初の1枚を、multi_mask_output = Trueの場合は最初を除く3枚を出力します。
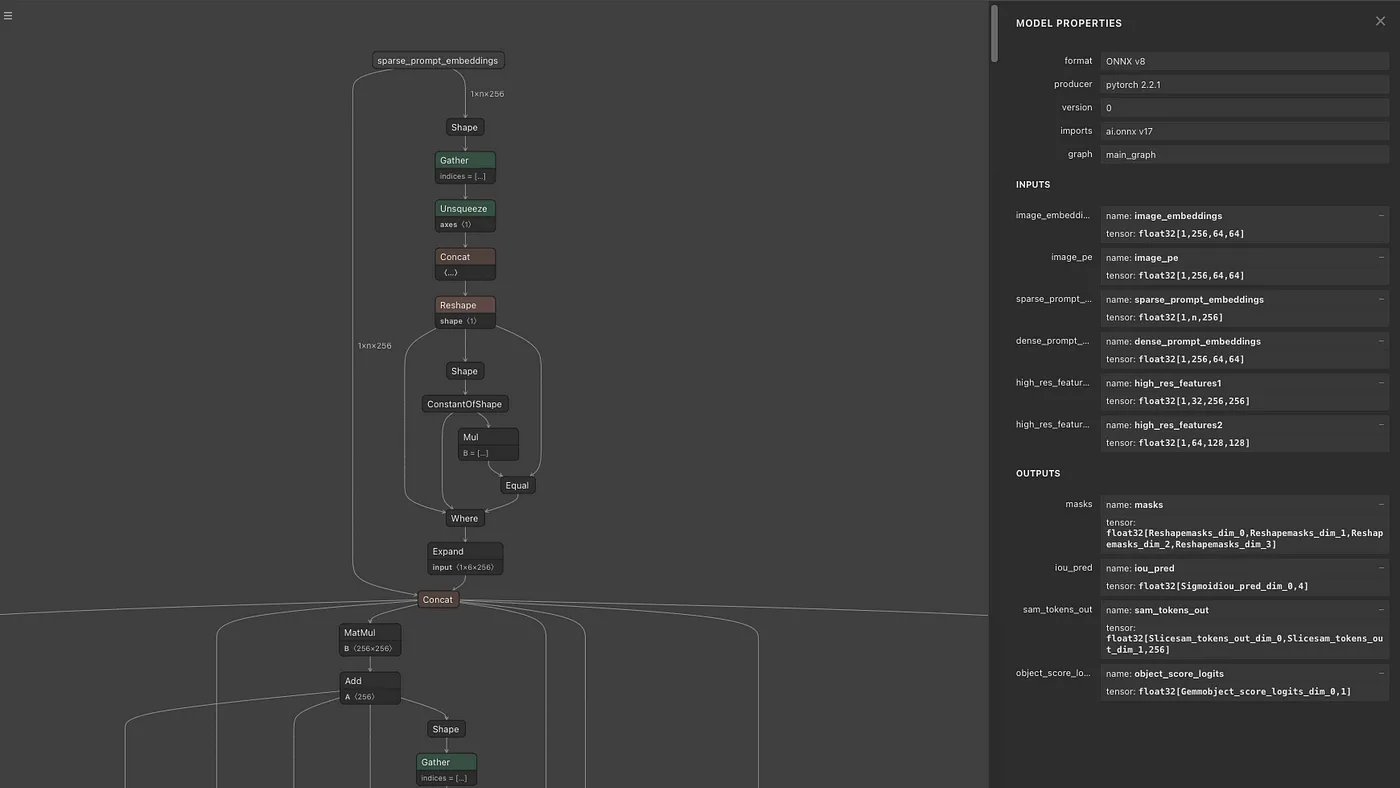
オプションでmax_hole_areaやmax_sprinkle_areaを有効にすると、マスク画像を穴埋めするように補正するアルゴリズムが適用されます。デフォルトでは無効になっています。
Prompt EncoderではPositionEmbeddingRandomを使用して、乱数で位置情報を符号化しています。Prompt Encoderに与えるPosition Embeddingの配列と、Mask Decoderに与えるPosition Embeddingの配列は一致させる必要があります。PositionEmbeddingのShapeは(1, 256, 64, 64)です。
動画モードの動作
動画モードでは、静止画モードに加えて、Memory Attentionが有効になります。
静止画モードと動画モードでは、Mask Decoderに与えるfeaturesを作成するロジックが異なります。静止画モードでは、現在のフレームのImage EncoderのBackboneの出力をMask Decoderに与えます。動画モードでは、静止画モードと同じ現在のフレームのImage EncoderのBackboneの出力であるcurrent_vision_featsと、memoryに保存しておいた以前のフレームのfeatsから、MemoryAttentionを適用することで、最終的なfeaturesを生成します。memoryにはプロンプト対象の1フレームと、現在のフレームの直前のNフレーム(最大6フレーム)が格納されます。
MemoryAttentionは2フレーム目から使用されます。2フレーム目の入力はcurr = (4096, 1, 256)、curr_pos = (4096, 1, 256)、memory = (4100, 1, 64)、memory_pos = (4100, 1, 64)になります。3フレーム目の入力はcurr = (4096, 1, 256)、curr_pos = (4096, 1, 256)、memory = (8200, 1, 64)、memory_pos = (8200, 1, 64)になります。
memoryには、cond_framesとして(4096, 64)のEmbeddingを最大でnum_maskmem = 7まで詰め込んだ後、(4, 64)のEmbeddingを最大でnum_obj_ptrs_in_encoder = 16まで詰め込みます。重要なフレームのEmbeddingは多く、それ以外の過去のフレームのEmbeddingは圧縮して詰め込む形になります。
MemoryAttentionにおいては、RoPE Attentionを使用しており、AttentionのQueryとKeyの各要素に対して、回転行列を適用することで、Position Embeddingを行います。RoPE AttentionのPosition Embeddingはcond_framesの領域(4096の倍数の領域)のみに適用します。RoPE Attentionの回転行列は4096要素分のみ用意されており、Key = memoryの長さの方が大きいため、repeatして拡張して使用します。Query = current_vision_featsの要素数は常に4096です。
https://github.com/naver-ai/rope-vit
MemoryAttentionの中では、_forward_saでSelf Attentionが、_forward_caでCross Attentionが計算されます。Self Attentionでは、current_vision_featsに対して処理が行われます。Cross Attentionでは、Self Attentionの結果とmemoryに対して処理が行われます。
MemoryAttentionの出力と、PromptEncoderの出力を、MaskDecoderに与えて、マスクを生成します。
生成したマスクは、次のフレームの処理のためにEmbeddingを計算して保存します。具体的に、現在のフレームのImageEncoderの出力と生成したマスクにMemoryEncoderを適用して計算したEmbeddingを保存しておき、次のフレームのMemoryAttentionに使用します。
画像認識解像度の変更
下記のIssueで、推論の解像度を1024から512に下げるすることで高速化したり、4096に上げることでPixel Perfectに近いマスクを取得する手法が議論されています。
https://github.com/facebookresearch/segment-anything-2/issues/138
解像度を512×512に下げると、Image EncoderのEmbeddingの次元数は4096から1024に削減されます。
ONNXへの出力
Memory AttentionをONNXに変換するためには、RoPE AttentionのComplex Tensorを2次元のTensorに置き換える必要があります。
https://github.com/facebookresearch/segment-anything-2/issues/186
SegmenyAnthing 2.1
2024/09/30にSAM2.1が公開されました。SAM2.1はSAM2と同じモデルアーキテクチャで、モデルの重みが更新されています。
また、cfgファイルにおいて、add_tpos_enc_to_obj_ptrsとproj_tpos_enc_in_obj_ptrsがtrueになっています。
これは、MemoryAttentionの入力となる、圧縮した過去フレーム情報であるobj_ptrsに対するposition_embeddingであるobj_posに影響します。
SAM2ではこの値は0ですが、SAM2.1ではSinによるposition_embeddingをnn.Linearでプロジェクションした値になります。
SegmentAnything2の使用方法
ailia SDKで静止画に対してSegmentAnyting2を使用するには下記のコマンドを使用します。posにはセグメンテーション対象の座標を指定します。
python3 segment-anything-2.py --pos 500 375 -i truck.jpgWEBカメラや動画に対してSegmentAnything2を使用するには下記のコマンドを使用します。
python3 segment-anything-2.py --pos 960 540 -v 0デモ動画に対してSegmentAnything2を使用するには下記のコマンドを使用します。
python3 segment-anything-2.py -v demoSegmentAnything2.1を使用するには、versionに2.1を与えます。デフォルトのバージョンは2になります。
python3 segment-anything-2.py -v demo --version 2.1https://github.com/axinc-ai/ailia-models/tree/master/image_segmentation/segment-anything-2

ax株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。ax株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。
SHARE THIS ARTICLE












