![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy.png)



こんにちは! おなかソフトの伊藤と申します! 普段はUnity関連のコンサルティングをしていたり、恵比寿Unity部という社会的弱者のためのゲーム開発教室ボランティアをしていたりします。
突然ですが、みなさんは「自律型AIアバターをつくりたい!」って思ったこと、ありませんか? いつもそばにいてくれるアンドロイドって、夢がありますよね! 本企画は、実際にゼロからAIアバターをつくるDIY企画です。はじめての方でもわかりやすくご紹介していますので、ぜひ挑戦してみてください。

自宅で手軽につくれる!? 自律型AIアバターづくりに挑戦
AIが一般化されて誰でも手軽に使えるようになった今、自分専用のAIアバターが自分でつくれちゃうのです。でも、実際に自律型AIアバターをつくろうとすると、何からはじめたらいいかわからないかもしれません。そういった「何から手をつけて良いかわからない」ときは、機能を分割して考えてみるのがおすすめです。
自律型AIアバターとは、人間の言うことを聞いて、ものを考え、答えを言葉として発する3Dアバター、ということですね。
つまり、分けて考えると、
1. 人間の言ったことをデジタルの文字にする(Speech To Text)
2. 文章を入力させると、その文脈に沿った答えが文章として返ってくる(LLM)
3. 文字を音声として再生させる(Text To Speech)
4. 言葉を発するアニメーションをするアバター(3DCG表現)
ということになります。
4はUnityで3Dキャラクターを表示して、音声に合わせてアニメーションさせれば表現できるでしょう。他の1から3はいろいろな選択肢があります。一般的に考えると、Python環境を導入して、その中で学習済みモデルを利用する方法でしょうか。ただ、それを実現させようとすると、以下のようなハードルがあります。
- Python 環境の導入
- モデルの選定
- Unityとの繋ぎ込み
- Etc…
そこで今回は、「ailia Unity SDK」を使うことでそのハードルを低くして、できるだけ簡単に自律型AIアバターをつくってみたいと思います。「ailia Unity SDK」は、Unityに入れるプラグインとして完結しているので、難しいことを考えずに導入することができますし、いったん入れてしまえば、すぐに学習済みモデルをUnityで利用できるようになります。開発者はプロダクト開発に集中できるわけで、これはすごくありがたいことですね。
ailia SDKの導入
今回使うのは
- Speech To Text に使う「ailia AI Speech」
- LLM に使う「ailia LLM」
- Text To Speech に使う「ailia AI Voice」
ailia SDK はコアモジュール(ailia SDK)とサブモジュール(ailia Audio、ailia Voice等)から成り立っています。一つひとつ入れていっても良いのですが、今回は手っ取り早く以下のサンプルをダウンロードして、利用していきましょう。
ailia Models Unity(ailia SDKのUnityサンプル集)
上記GitHubサイトの「Code」→「Download ZIP」で、ローカルにダウンロードしましょう。展開したプロジェクトをUnity Hubで「追加」→「ディスクから加える」で追加します。
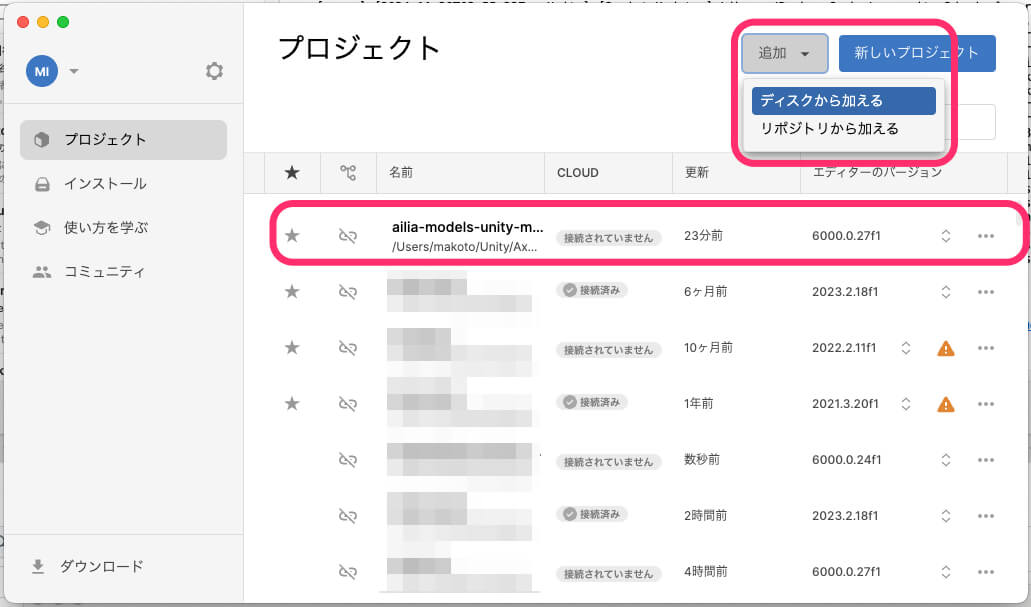
利用するUnityバージョンは2021.3.10f1となっています(202411月28日現在)が、最新のUnity6でも利用可能です。今回は最新版のUnity6000.0.27f1で進めてみます。追加した「ailia-model-unity-master」をUnity Hubで選択して、Unityでプロジェクトを開きましょう。
Unityで開いたら試しにサンプルを動かしてみましょう。
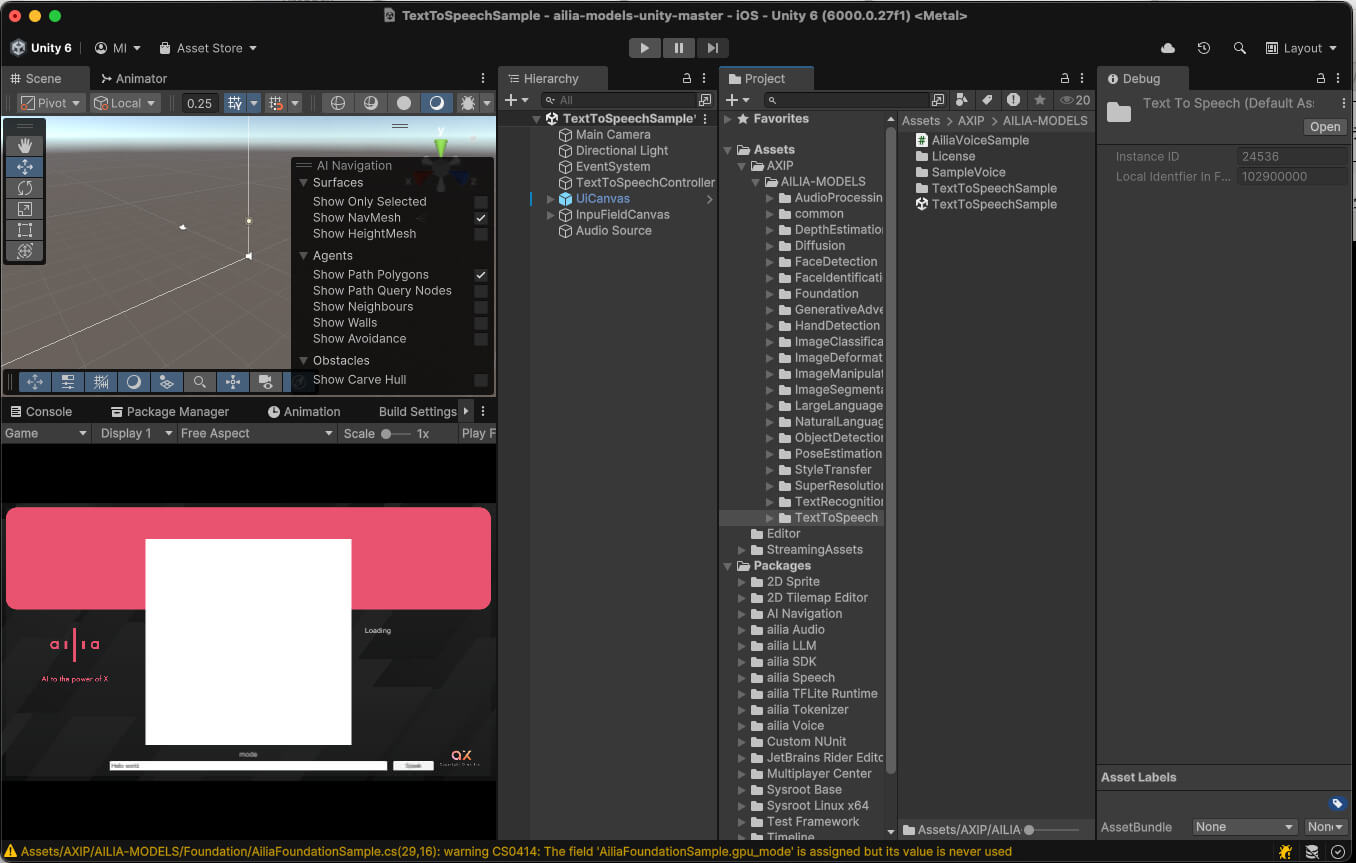
Assets/AXIP/AILIA-MODELS/TextToSpeech/TextToSpeechSample
上記をUnityで開いて、Playしてみましょう。すると、必要なモデルをその場でロードが始まるので、ロードが完了するまで待ちましょう。
ロードが完了したら、右下の「Speak」ボタンを押すと「はろーわーるど」という女性の声が聞こえるはずです。下の文字を入力するところに自由な文字列を代入することで、自由な発話ができますので、いろいろ試してみてください。
次に違うサンプルを試してみましょう。
Assets/AXIP/AILIA-MODELS/SpeechToText/SpeechToTextSample
上記をUnityで開きます。
プレイするとモデルのロードが始まります。先ほどと同じように一旦終わるまで待ちましょう。
ロードが終わったらマイク入力で何かを発声すると、Gameシーンで右側に喋った内容が表示されるのを確認できます。
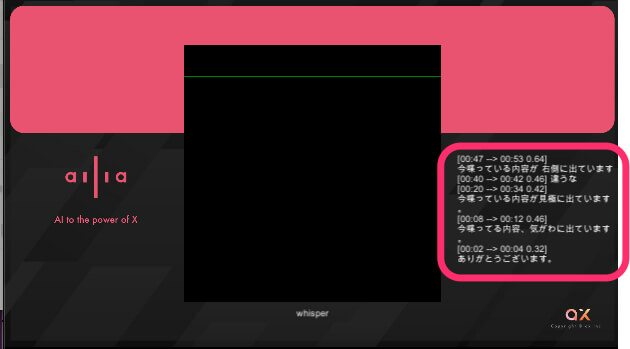
ちなみに今、試したサンプルで何か気がつかれたでしょうか。実は、「自律型AIアバター」で必要な「Speech To Text」と「Text To Speech」はこの試したサンプルで実現ができているのです。つまり、後者のサンプルを使って、音声をテキストデータに変換し、前者のサンプルを使って、テキストデータを発話させれば、自律型AIアバターは実現ができるということです。どうでしょうか、簡単に感じたのではないでしょうか。あとは中間の考える部分をLLMで実現するだけ、ということになります。
次回は、今回試したふたつのサンプルを利用して、簡単な「おうむ返し」デモをつくっていきます。
おなかソフト 伊藤 周 氏
Unityコンサルタンティング業務やVRゲーム開発を行う企業「おなかソフト」の代表取締役。Unityを学ぶ環境と居場所を提供し、これらの機会創出を目的に活動する子どもたちのための「恵比寿Unity部」なども展開。子ども達の自主性を最優先とし、Unityに限らずやりたい事ができる環境と居場所を提供している。
https://onaca.jp/
SHARE THIS ARTICLE












