ailia SDKで使用できる機械学習モデルである「VoiceFilter」のご紹介です。エッジ向け推論フレームワークであるailia SDKとailia MODELSに公開されている機械学習モデルを使用することで、簡単にAIの機能をアプリケーションに実装することができます。
VoiceFilterの概要
VoiceFilterは2020年5月に公開された音声分離モデルです。GoogleAIによって開発されました。複数人が同時に喋っている音声ファイルから、任意の人物の音声だけを抽出することが可能です。
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by…
GitHub – mindslab-ai/voicefilter: Unofficial PyTorch implementation of Google AI’s VoiceFilter…
Hi everyone! It’s Seung-won from MINDs Lab, Inc. It’s been a long time since I’ve released this open-source, and I…
VoiceFilterのアーキテクチャ
近年の音声認識の性能は高くなっていますが、複数人が存在する環境での音声認識の性能は十分ではありません。この問題に対して、Speech Separationによって、複数人が喋っているNoisyな音声から、特定の人物の音声だけを抽出することは、音声認識の性能向上に重要です。
従来方式は、複数人が喋っている音声から、複数人の音声を分離します。しかし、現実の応用では、現在、何人が喋っているかを把握することが困難です。また、Speakerをラベル付けする必要があり、Deep ClusteringやDeep Attractor Networkなどを使用する必要があります。
この問題に対して、提案方式では、抽出したい人の声以外をノイズとして扱います。また、抽出したい人の声を、事前に録音した音声として与えます。この方法は、従来のSpeech Separtionに近いですが、Speakerに依存しています。このタスクを、Speaker Dependent Speech Separatin (Voice Filter)として定義します。
VoiceFilterでは、Speaker Recognition Networkと呼ばれる個人の声の特徴を示すd-vectorを抽出するモデルと、Spectrogram masking networkと呼ばれる複数人が喋っている音声とd-vectorから、特定の人の声を抽出するモデルの2種類が使用されています。
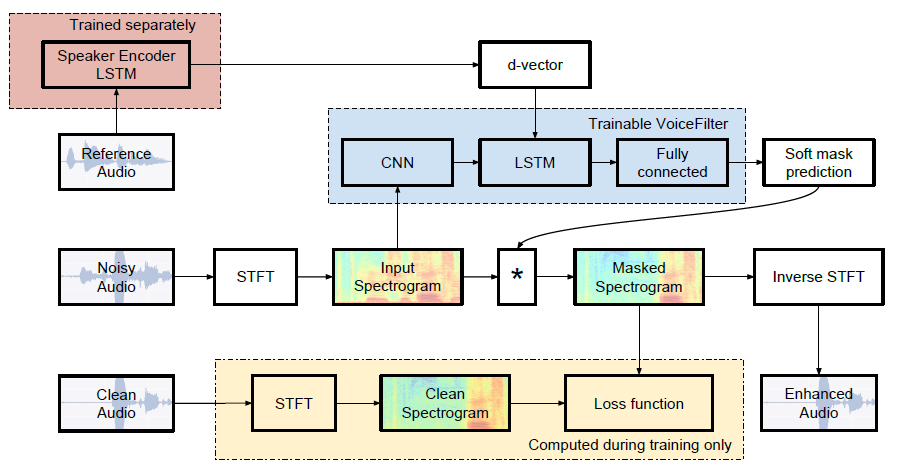
Speaker Recognition Networkでは、3-layer LSTMをベースとして、ロバストなSpeaker Embedding Vectorsを計算します。1600msのwindowでSpectrogramを取得し、256次元のd-vectorを出力します。windowは50% overlapし、L2正規化した上で、全windowのd-vectorを平均化して使用します。
Voice Filterでは、STFTによってNoisy Audio(複数人の声が混ざった音声)からmagnitude spectrogramを計算、d-vectorからsoft maskを計算し、magnitude spectrogramに対してsoft maskを乗算、Noisy AudioのPhase情報を加えた後、SIFTして出力波形を得ます。
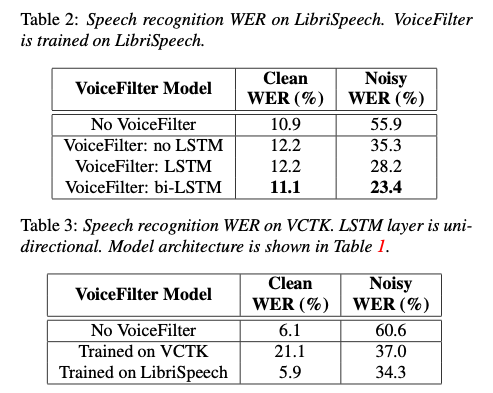
精度評価においては、WER (Word error rate)を使用します。YouTube datasetを使用し、Speech Recognizerの音声認識率を評価に使用します。Speech RecognizerにはLibriSpeechとVCTKを使用します。
Clean WERはclean audioに対するWER、Noisy WERはnoisy audioに対するWERです。VoiceFilterを使用することで、noisy audioに対するエラー率が、55.9%から23.4%まで低減します。
VoiceFilterの使用方法
ailia SDKでVoice Filterを使用するには下記のコマンドを使用します。複数人が喋っているmixed.wavと、抽出したい人が喋っているref-voice.wavを与えることで、特定の人物の声を抽出します。
$ python3 voicefilter.py --input mixed.wav --reference_file ref-voice.wav
ailia-models/audio_processing/voicefilter at master · axinc-ai/ailia-models
Audio file Reference audio for d-vector Input an audio file that is spoken by multiple people and an audio file that…
ax株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。ax株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。