ntroducing “VoiceFilter,” a machine learning model available for use with the ailia SDK. By utilizing machine learning models published on ailia MODELS and the ailia SDK, an edge-oriented inference framework, you can easily implement AI functionality into your applications.
Overview of VoiceFilter
VoiceFilter is a voice separation model released in May 2020, developed by GoogleAI. It allows for the extraction of the voice of a specific individual from audio files where multiple people are speaking simultaneously.
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
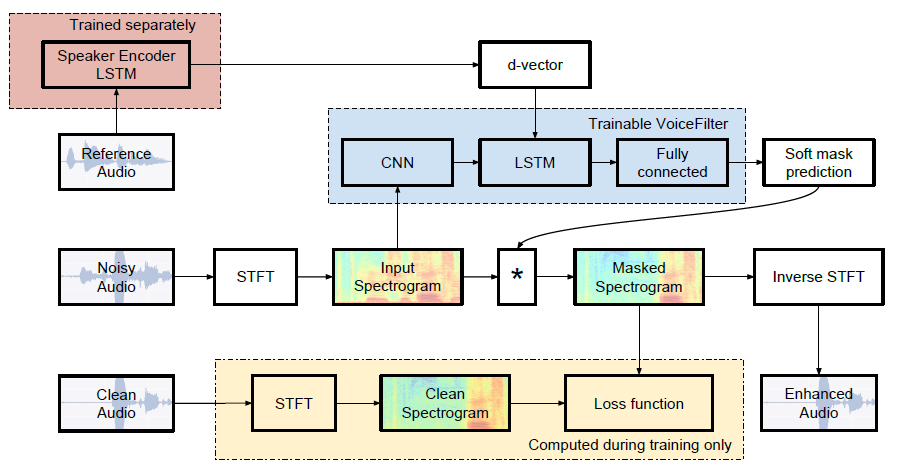
VoiceFilter Architecture
While the performance of speech recognition has improved in recent years, its performance in environments with multiple speakers is still not optimal. Addressing this issue, separating the voice of a specific individual from noisy audio where multiple people are speaking is crucial for improving speech recognition performance.
Traditionally, methods have separated the voices of multiple speakers from audio files where multiple people are speaking. However, in practical applications, it is difficult to determine how many people are currently speaking. Moreover, labeling speakers is necessary, requiring the use of techniques such as Deep Clustering or Deep Attractor Network.
To address this problem, the proposed method treats voices other than the one to be extracted as noise. Additionally, the voice to be extracted is provided as pre-recorded audio. While this method is similar to traditional Speech Separation, it relies on the speaker. This task is defined as Speaker Dependent Speech Separation (Voice Filter).
VoiceFilter utilizes two models: the Speaker Recognition Network, which extracts d-vectors representing individual voice characteristics, and the Spectrogram masking network, which extracts the voice of a specific person from audio where multiple people are speaking, based on the d-vectors.
Source: https://github.com/mindslab-ai/voicefilter
In the Speaker Recognition Network, robust Speaker Embedding Vectors are computed based on a 3-layer LSTM. A spectrogram is obtained with a 1600ms window, outputting a 256-dimensional d-vector. The window overlaps by 50%, and after L2 normalization, the d-vectors from all windows are averaged.
In Voice Filter, a magnitude spectrogram is calculated from Noisy Audio (audio with multiple voices mixed) using STFT. A soft mask is calculated from the d-vector, multiplied by the magnitude spectrogram, the Phase information of the Noisy Audio is added, and then ISTFT is performed to obtain the output waveform.
In terms of accuracy evaluation, WER (Word error rate) is used. The YouTube dataset is employed, and the speech recognition rate of the Speech Recognizer is evaluated. LibriSpeech and VCTK are used for the Speech Recognizer.
Clean WER refers to the WER for clean audio, while Noisy WER refers to the WER for noisy audio. Using VoiceFilter reduces the error rate for noisy audio from 55.9% to 23.4%.
Source: https://arxiv.org/abs/1810.04826
How to Use VoiceFilter
To use Voice Filter with the ailia SDK, use the following command. By providing mixed.wav (audio with multiple people speaking) and ref-voice.wav (audio of the person whose voice you want to extract), you can extract the voice of a specific individual.
$ python3 voicefilter.py –input mixed.wav –reference_file ref-voice.wav
ax Inc. is a company that specializes in practical AI solutions, developing the ailia SDK, which enables high-speed inference using GPUs across platforms. From consulting to model creation, SDK provision, AI-based application/system development, and support, ax Inc. provides a comprehensive solution for AI-related needs. Please feel free to contact us.
Source: