Introduction to “AutoSpeech,” a machine learning model available in the ailia SDK, is provided below. With ailia SDK and ailia MODELS, which are edge inference frameworks, machine learning models can be easily implemented in applications.
Overview of AutoSpeech
AutoSpeech is a machine learning model capable of performing individual identification from speech. By inputting two audio files and calculating the feature vectors of each audio, it can output the similarity between the two audio files. By storing the feature vectors of the target individual’s speech in a database, individual identification becomes possible. It can be applied to voice-based biometric authentication or transcription tasks, where the speaker needs to be identified from the audio.
AutoSpeech: Neural Architecture Search for Speaker Recognition
Speaker recognition systems based on Convolutional Neural Networks (CNNs) are often built with off-the-shelf backbones…
AutoSpeech Architecture
There are two applications for Speaker Recognition: Speaker Identification (SID) and Speaker Verification (SV). In recent years, End2End Speaker Recognition has shown high performance.
In End2End Speaker Recognition, feature extraction is performed on a frame-by-frame basis using CNNs or RNNs, followed by conversion to fixed-length Speaker Embeddings (d-vectors) using a Temporal Aggregation Layer. Similarity is calculated using methods such as cosine similarity on the obtained Embeddings.
Traditionally, architectures such as VGG or ResNet have been used for Feature Extractors. However, these architectures are optimized for image recognition and may not be ideal for Speaker Recognition.
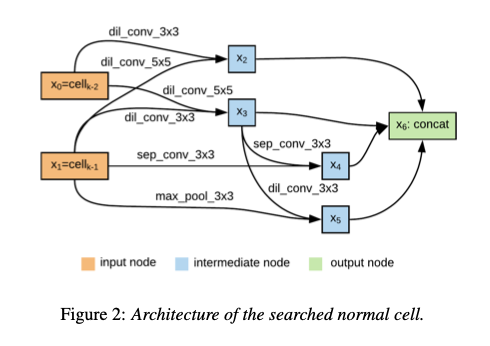
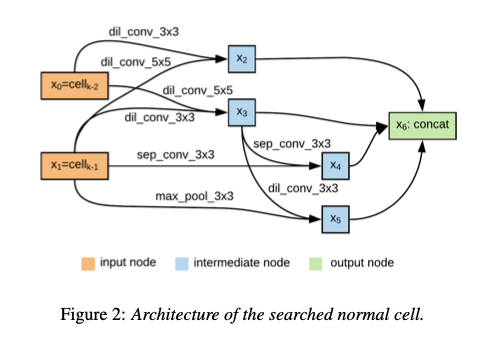
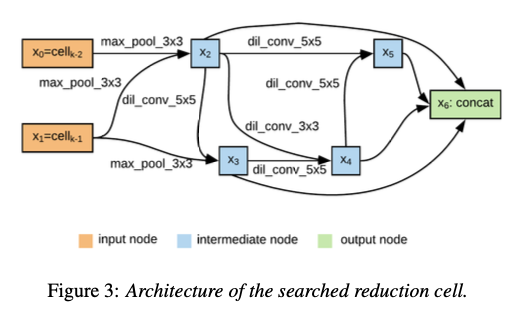
AutoSpeech employs Neural Architecture Search to find the optimal network architecture. The search space consists of the following set of layers.

The searched architecture consists of Normal Cells that do not change the resolution (dimension) and Reduction Cells that reduce the resolution (dimension). For example, in VGG, Conv -> Relu corresponds to Normal Cells, and MaxPooling corresponds to Reduction Cells. The final model architecture is obtained by stacking these cells eight times.
Training and evaluation are performed using the VoxCeleb1 dataset.
VoxCeleb
VoxCeleb1 contains over 100,000 utterances for 1,251 celebrities, extracted from videos uploaded to YouTube. 26/10/2017…
Evaluation results are as follows. The proposed method outperforms those using VGG or ResNet.
The sampling rate of the processed audio files is 16kHz, and processing is performed on STFT-transformed spectra. The audio files are divided into frames, and the feature vectors of each frame are calculated. The mean of all frames is taken as the final fixed-length feature vector. Similarity is calculated using cosine similarity by normalizing the feature vectors and taking the dot product.
Using AutoSpeech
You can use the following command to input two audio files and output their similarity.
$ python3 auto_speech.py --input1 wav/id10270/8jEAjG6SegY/00008.wav --input2 wav/id10270/x6uYqmx31kE/00001.wav
ailia-models/audio_processing/auto_speech at master · axinc-ai/ailia-models
Audio file Wav file from The VoxCeleb1 Dataset https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html Default input…
The output example shows “match” if the similarity is greater than a threshold.
INFO auto_speech.py (229) : Start inference...
INFO auto_speech.py (243) : similar: 0.42532125
INFO auto_speech.py (245) : verification: match (threshold: 0.260)
Training is conducted on English datasets, but the congratulatory messages “Congratulations” and “Well done” from energetic girls have a similarity of 0.41 and match. The calm female voice saying “Congratulations” and “You passed” has a similarity of 0.80 and match. “Congratulations” from an energetic girl and “Congratulations” from a calm female voice have a similarity of 0.228 and unmatch, demonstrating applicability to Japanese audio as well.
Sound Effect Lab – Download Free, Commercial-Free Sound Effects
You can download hundreds of high-quality, royalty-free sound effects from Sound Effect Lab, offering a wide range of free materials.
ax Inc. is a company that specializes in practical AI solutions, developing ailia SDK for cross-platform GPU-accelerated inference. From consulting to model creation, SDK provision, AI-based app/system development, and support, ax Inc. provides a total solution for AI, so feel free to contact us.