![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy.png)
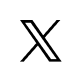



高精度で高速な音声認識モデルであるWhisper Large V3 Turboのご紹介です。
Whisper Large V3 Turboの概要
Whisper Large V3 Turboは、OpenAIが2024年10月に公開したWhisperの最新モデルです。Large V2の精度を維持しながら、大幅な高速化を実現しています。
https://github.com/openai/whisper/discussions/2363
Whisper Large V3 Turboのアーキテクチャ
Whisper Large V3 Turboは、Whisper Large V3のDecoderのデコーダ層の数を32から4に削減したモデルです。4層というのはtinyモデルと同じ層数で、大幅な高速化を実現しています。
この実装は、Distil-Whisperに触発されており、小さなデコーダを使用することで、精度を維持しながら速度が大幅に改善することを参考にしています。
Disil-Whisperでは、蒸留を使用していますが、Whisper Large V3 TurboはWhisperの元のデータセットで再学習されています。翻訳データは含まれていないので、翻訳モードを使用することはできません。
推論速度と精度の比較です。横軸が推論速度で、右に行くほど高速です。turboは、tinyとbaseの間の推論速度を実現しています。縦軸が精度(エラーレート)で、下に行くほど高精度です。Large V2と同等の精度を達成しています。
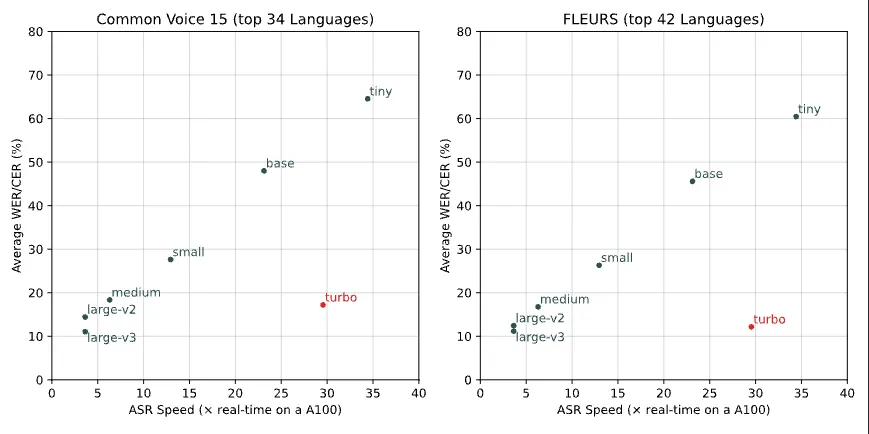
言語別の制度です。タイ語や広東語で精度が低下していますが、日本語ではLarge V2と同等の精度を持っています。
Whisper Large V3 TurboのモデルアーキテクチャはWhisper Large V3と互換性があります。そのため、Whisper Large V3の推論コードをそのまま使用することが可能です。
Whisper Large V2とV3について
Whisper Large V2は単にLargeと呼ばれることもある、Whisperの初期からある高精度なモデルです。Whisper Large V3は、2023年11月に公開された新しいモデルで、対応言語が広東語に対応して99から100に、MelSpectrumのbinが80から128に拡張されています。
Whisper Large V3 Turboにおける翻訳
通常のWhisperでは、SOTシーケンスを使用することで、TRANSCRIBEとTRANSLATEを指定可能です。TRANSCRIBEでは入力言語のまま、TRANSLATEでは英語に翻訳した結果が出力されます。Whisper Large V3 Turboの場合、TRANSLATEを指定しても、翻訳は行なわれず、入力言語のまま出力されます。
Whisper Large V3 Turboの使用方法
ailia SDKでWhisper Large V3 Turboを使用するには、下記のコマンドを使用します。
$ python3 whisper.py --input input.wav -m turbohttps://github.com/axinc-ai/ailia-models/tree/master/audio_processing/whisper
Whisper Large V3 TurboはWhisper Large V3と互換性があるため、ailia AI Speechのモデルを差し替えるだけで実行可能です。そのため、ライブラリのアップデート不要で、Unityからも使用可能です。
https://github.com/axinc-ai/ailia-models-unity/pull/144
ailia AI SpeechのPython Packageからも使用可能です。
https://pypi.org/project/ailia-speech/
Whisper Large V3 Turboの評価
実際にailia SDKとWhisper Large V3 TurboをM2 MacのCPUで使用した場合、40secの音声データを変換するための推論時間は下記のようになります。
small 9432 ms(encoder 659ms decoder 37ms)
turbo 18363 ms(encoder 2878ms decoder 37ms)
medium 29323 ms(encoder 2277ms decoder 353ms)
モデル構成としては、EncoderはLarge V3と同等なので、Encoderが重く、Decoderが大幅に高速なっています。
Encoderは30secを一度で推論し、Static Shapeでフレーム間でTensorのShapeは変化しません。対して、DecoderはDynamic Shapeでフレーム間でTensorのShapeが変化するため、シェーダの再構築が必要になります。Whsper Large V3 TurboはEncoderが重く、Decoderが軽いため、GPUで高速化の効果が得られやすいアーキテクチャになっています。
M2 MacのGPUで使用した場合、下記のパフォーマンスになります。
small 15588 ms(encoder 310ms decoder 69ms)
turbo 15775 ms (encoder 2129ms decoder 37ms)
medium 57175ms (encoder 1078ms decoder 241ms)
smallやmediumでは、CPUの方が高速ですが、turboではGPUの方が高速になります。
ax株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。ax株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。
SHARE THIS ARTICLE












