![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy_en.png)



This is an introduction to「AutoSpeech」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
AutoSpeech is a machine learning model that can identify individuals from their speech. By inputting two audio files and generating the feature vectors of each recording, the degree of similarity between the two files can be computed. This method can be used to match a recording against feature vectors of people voices stored in a database for identification. It can be used for voice biometric authentication, or identifying speakers in speech transcriptions.
AutoSpeech: Neural Architecture Search for Speaker Recognition
Architecture
There are two main tasks for speaker recognition: Speaker IDentification (SID) and Speaker Verification (SV). In recent years, end-to-end speaker recognition systems have emerged and achieved state-of-the-art performance.
In end-to-end speaker recognition, a Convolutional Neural Network (CNN) or Recurrent Neural Network (RNN) is used as feature extractor for each audio frame, which is then turned into a fixed length speaker embedding (d-vector) by a a temporal aggregation layer. Finally, cosine similarity is used on those embeddings to produce the final speaker identification decision.
VGG and ResNet architectures are usually used for the feature extraction. However, these architectures are intended for image identification and are not optimal for speaker recognition.
AutoSpeech uses Neural Architecture Search (NAS) to search for the best network architecture. The search space is a set of the following layers:

The NAS process is made of two types of neural cells: normal cells that keep the spatial resolution of the feature tensor (number of dimensions), and reduction cells that shrinks the resolution. For example, in VGG Conv -> Relucorresponds to a normal cell and MaxPooling corresponds to a reduction cell. These cells are stacked 8 times to form the final model architecture.
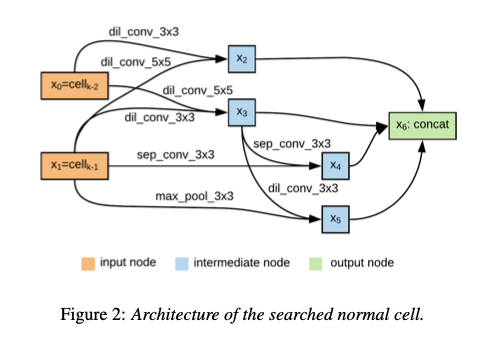
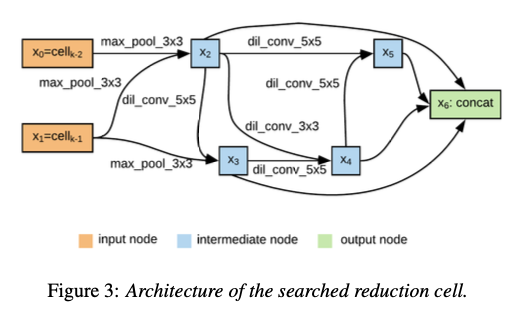
VoxCeleb1 dataset was used for training and evaluation.
The evaluation results are shown below. The proposed method out performs those based on VGG and ResNet.
The processing is performed on STFT spectrum data of audio files at sampling rate 16 kHz. The audio file is divided into frames, on which the feature vector is computed, and the mean of all frames is taken as the final fixed-length feature vector. The cosine similarity metric is then calculated by normalizing and inner-product of feature vectors.
Usage
The following command will allow you to input two audio files and output the similarity.
$ python3 auto_speech.py --input1 wav/id10270/8jEAjG6SegY/00008.wav --input2 wav/id10270/x6uYqmx31kE/00001.wav
ailia-models/audio_processing/auto_speech
Here is an example output. If the similarity is greater than the threshold, the person is identified as the same person and the output is “match”.
INFO auto_speech.py (229) : Start inference…
INFO auto_speech.py (243) : similar: 0.42532125
INFO auto_speech.py (245) : verification: match (threshold: 0.260)
The training is done on dataset made of speeches in English, but let’s test it on Japanese sentences using the audio file library below.
Sound Effects Lab – Download free, commercial free, report-free sound effects
Various inferences showed that sentences from the same person matched with a similarity between 0.41 and 0.80. An example of similar sentences (same words) from two different people unmatched with a similarity 0.228. Therefore the same model can also be used for other languages, in that case Japanese.
ax Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ax Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.
SHARE THIS ARTICLE









