![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://blog.ailia.ai/wp-content/themes/ailia-media-2024/assets/images/main_copy_en.png)



ailia SDKで使用できる機械学習モデルである「DPT」のご紹介です。エッジ向け推論フレームワークであるailia SDKとailia MODELSに公開されている機械学習モデルを使用することで、簡単にAIの機能をアプリケーションに実装することができます。
This is an introduction to「DPT」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
DPT (DensePredictionTransformers) is a segmentation model released by Intel in March 2021 that applies vision transformers to images. It can perform image semantic segmentation with 49.02% mIoU on ADE20K, and it can also be used for monocular depth estimation with an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network.
Vision Transformers for Dense Prediction
Architecture
In DPT, vision transformers (ViT)are used instead of convolutional network. Using transformers allows to make more detailed and globally consistent predictions compared to convolutional networks. In particular, performance is improved when a large amount of training data is available.
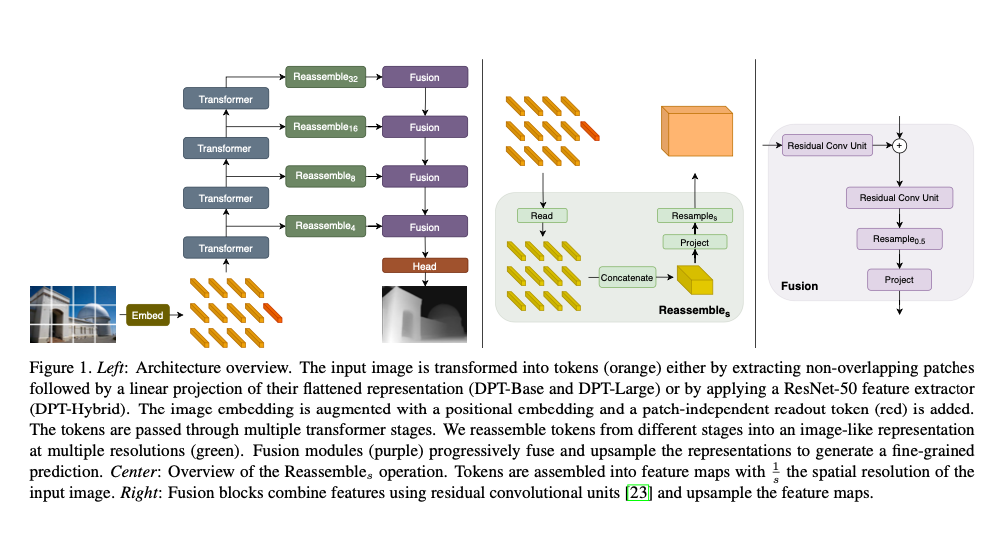
The encoder divides the image into tiles, which are then tokenized (Embed in the graph above), and transformers process it. The process marked as Embedis a patch-based method to divide image into tiles, and tokenize the pixel feature map obtained by applying ResNet50 to the input image.
The decoder in DPT converts the output of each resolution of the transformer into an image like representation and uses a convolutional network to generate the segmentation image.
There are three model architectures defined in DPT: ViT-Base, ViT-Large, and ViT-Hybrid. ViT-Base performs patch-based embedding and has 12 transformer layers. ViT-Large performs the same embedding as ViT-Base, but has 24 transformer layers and a larger feature size. ViT-Hybrid performs embedding using ResNet50 and has 12 transformer layers.
DPT accuracy
DPT sets a new state of the art for the semantic segmentation task on ADE20K, a large data set with 150 classes.
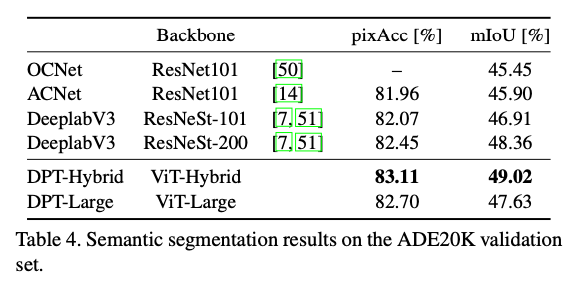
It is also the state of the art after some fine-tuning on smaller datasets such as NYUv2, KITTI, and Pascal Context.
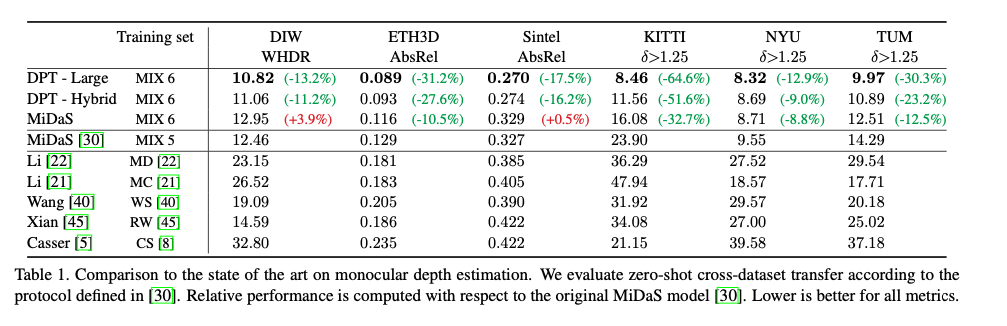
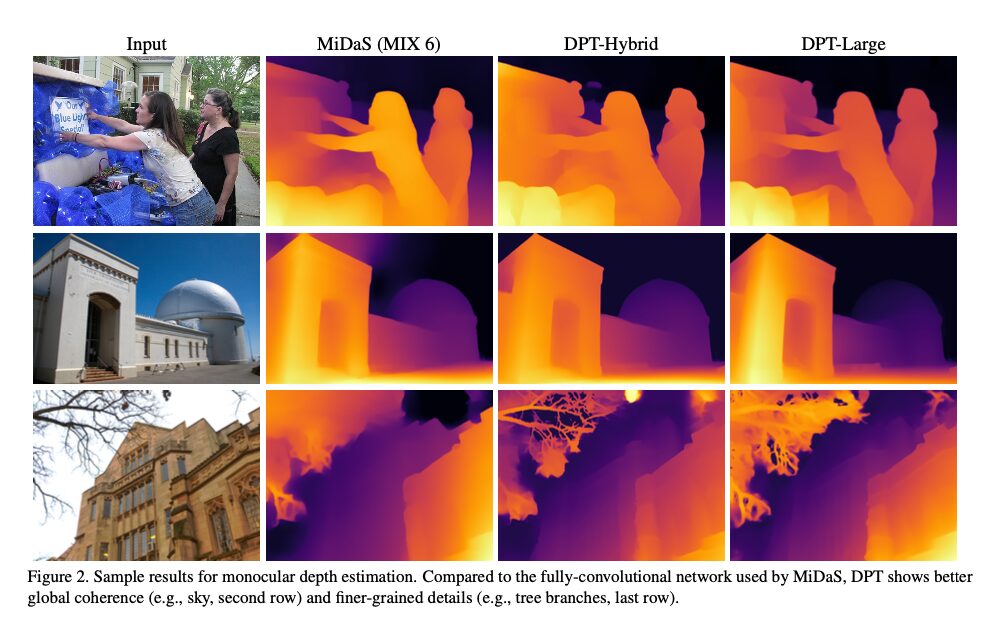
Below is a comparison of MiDaS and DPT for depth estimation. DPT is able to predict the depth inmore detail. It can also improve the accuracy of large homogeneous regions and relative positioning within an image, which is a shortcoming of convolution networks.
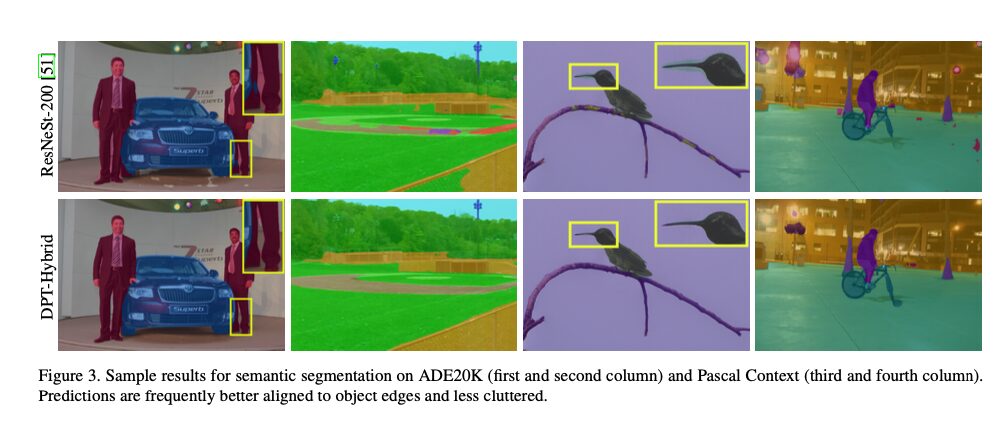
Below is a comparison for the segmentation task. DPT tends to produce more detailed output at object boundaries, and it tends to produce less cluttered output in some cases.
DPT Usage
You can use the following commands to perform segmentation and depth estimation on the input images with ailia SDK.
$ python3 dense_prediction_transformers.py -i input.jpg -s output.png --task=segmentation -e 0
$ python3 dense_prediction_transformers.py -i input.jpg -s output.png--task=monodepth -e 0
Here is a result you can expect.
ax Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ax Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.
SHARE THIS ARTICLE









